排查kubernetes job重试次数异常问题
问题
我司平台上支持用户创建k8s中job类型的负载,今天接到一个bug:设置了job的失败后重试次数,但是在集群里实际的重试次数并不是在平台上设置的次数。
关于k8s中job类型负载的重试次数,主要由yaml中的.spec.backoffLimit决定。如果由job控制器创建出来的pod没有正常退出,控制器会多次创建新的pod重试,直到重试次数达到了backoffLimit。最终如果到达了重试次数上限且无一成功,则job的状态会被置为Failed。
排查
- 首先当然是确定平台生成的job yaml中.spec.backoffLimit字段值是否准确,经过对比发现无误。
- 排除了我司业务逻辑的问题后,主要问题应该是在边缘的k8s集群中了。在开发环境尝试复现发现无此问题;在出现bug的集群中多次尝试复现,并且每次都改变backoffLimit的值,观察job在状态变为Failed之前经过的失败次数,发现重试次数会比backoffLimit值大,且大于backoffLimit多少是不固定的。
- 经过上一步测试,可以看到集群controller-manager也就是job控制器的行为是异常的,因此想到查看集群controller-manager的日志。
- 为了查看controller-manager的日志,首先要明确一下集群controller-manager组件的部署方式,比如是否有高可用,是否以pod形式跑在集群里等。查看了kube-system命名空间pod后,没有看到controller-manager的pod。去master1节点上用
systemctl status kube-controller-manager查看controller-manager状态发现状态竟然是down掉的。既然如此猜测应该是有多个controller-manager实例。 - 分别查看另外两个master节点的controller-manager状态,并用
journalctl -u kube-controller-manager --since "2021-09-10 20:20:00"命令过滤出日志,再定位一下job的命名空间等关键字,便可以得出结论。
结论
在两个controller-manager的日志中可以看到大量频繁的重启、leader选举相关的日志,并且看到日志中和job相关的几行报错,提示控制器未能同步job的状态。更进一步可以发现,报错的行数,正好是job失败前重试次数和yaml中设置的.spec.backoffLimit相比多出的次数。
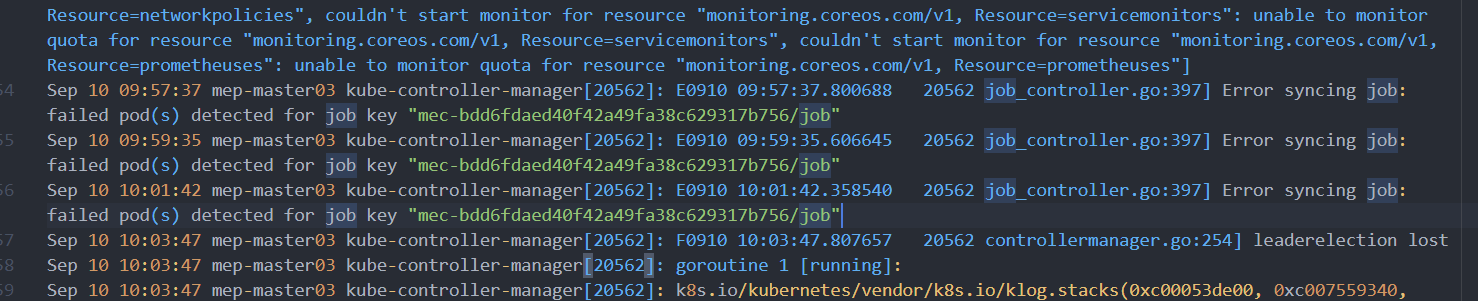
在job_controller.go中可以看到相关的代码如下:
func (jm *Controller) processNextWorkItem() bool {
key, quit := jm.queue.Get()
if quit {
return false
}
defer jm.queue.Done(key)
forget, err := jm.syncHandler(key.(string))
if err == nil {
if forget {
jm.queue.Forget(key)
}
return true
}
utilruntime.HandleError(fmt.Errorf("Error syncing job: %v", err))
jm.queue.AddRateLimited(key)
return true
}本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。