开源贡献:为metallb实现layer2模式下状态展示功能
背景
- metallb缺少对组件内部状态的展示,导致故障排查比较困难
- 提了issue,发现已有proposal,加入相关的状态展示类功能,基于k8s CRD实现
- 提出可以分配给我来做,正好我也有兴趣,可谓是王八看绿豆看对眼儿了,一拍即合,于是该功能的实现被分配给了我,接下来就开始实现:#2158
贡献前须知
之前大多数的开源贡献是改bug类型,这是首次为社区做正式的功能开发。同时这也是第一次参与metallb社区的工作,所以首先需要阅读一下项目的贡献前须知,熟悉一些纲领、原则性的内容。
-
Code of Conduct:主要是对社区氛围、基本规范的要求,是一些比较基本的规则。By the way,开篇第一段的社区愿景写得很美好。首次阅读,给人以一种即将开启通向“大同世界”的大门。
PS:实际上在合作的几个月过程中,和项目的两位owner的交流都比较顺利、愉快。两位owner都十分礼貌、友好,且体现出了很高的专业程度。经过这一个功能的开发,我确实学到了很多在目前公司学不到的东西。
-
-
代码变更流程:PR+design,如果是比较初步的探讨,那么先发issue
-
DCO:之前向kubeedge提交代码时遇到过,实践起来通常很简单,就是commit时记得设置sign-off。但是如果某个commit忘记了,就需要rebase修改commit,就相对烦人了一些。所以一定要在提交commit前配置好sign-off选项
-
介绍了代码仓库的工程结构
❯ tree -L 1 -d . ├── api ├── charts ├── config ...... 部署相关,比如config/manifests/metallb-native.yaml ├── configmaptocrs ├── configsamples ├── controller ...... k8s控制器 ├── design ├── dev-env ├── e2etest ├── frr-tools ├── internal ...... 库 ├── speaker ...... 代答模块 ├── troubleshooting └── website ...... 官网 15 directories ❯ tree -L 1 -d ./internal ./internal ├── allocator ...... 管理IP地址 ├── bgp ...... BGP相关实现 ├── config ...... 和metallb的configmap交互 ├── ipfamily ├── k8s ...... 和集群交互,屏蔽一些和k8s交互的复杂性 ├── layer2 ...... arp/ndp相关实现 ├── logging ...... 日志,把klog和go的标准库log整合 ├── pointer ├── speakerlist └── version 11 directories -
开发工具介绍。除了常见的工具外,额外提到了一个叫做invoke的工具,是一个python写的任务管理工具,类似于Make。只不过任务的编写用python实现,然后通过invoke实现可命令行调用的各种任务,方便开发。后面会专门整理项目中关于该工具的用法和一些坑。
-
如何进行代码的本地开发。介绍了如何让controller和speaker在本地跑起来,并连接开发环境集群
-
双远程仓库模式(fork&add remote)。
git remote add fork git@github.com:<your-github-user>/metallb.git实际上在后面开发过程中能明显体会到,双远程仓库的模式不如单远程仓库的模式方便,除非非常习惯这种多远程仓库的工作模式。否则后续的
git push/pull/rebase/merge等操作都需要关注选择远程仓库。且现在github对于fork仓库和源仓库的很多操作都已经支持在网页上快速完成了,所以双远程仓库就显得更没有必要了,只需要把更多精力放在自己的远程仓库即可。 -
commit message注意事项。有很多细节,比如72字符换行等,更详细的内容可参考:How to Write a Git Commit Message (cbea.ms)
-
概要设计
首先,梳理一下本次开发功能所在的设计文档:https://github.com/metallb/metallb/blob/main/design/crd-status.md
总体思想:由于metallb的工作原理,很多配置是集群级别的,但是实际工作中,状态和node强相关,这部分状态未经暴露,影响观测和debug。因此该设计尝试使用CR暴露metallb配置、BGP状态、Layer2模式状态等。
实际上公司项目在使用metallb的过程中,确实遇到了这方面的问题,对效率的影响是比较明显的。因为每次发现LB service不通,就需要先操作一番确定一下到底是哪个speaker在负责目标service的arp广播。
本次我负责实现的就是Layer2模式下的状态展示功能,因此后文将围绕metallb layer2模式下的状态暴露功能展开描述细节。
另外,官方文档也对不同模式的工作原理和特点做了基本的介绍,可以加深对项目原理的理解。
通过阅读上述的一些入门级别的文档,可以发现metallb这个项目的文档覆盖面还是比较广的,从比较宏观的概要,到设计,再到帮助开发者快速上手的文档,都能很大程度上降低新手的上手难度。和公司里很多靠人传人、摇人的方式形成了鲜明的对比。
CRD设计
在上面提到的设计文档中,已经给出了CRD字段设计,不可谓不贴心。有了CRD的设计,基本上要做的功能方向就已经很明确了。
yaml:
apiVersion: metallb.io/v1beta1
kind: ServiceL2Status
metadata:
name: service1
namespace: servicenamespace
labels:
metallb.io/node: worker0
metallb.io/service: service1
status:
node: worker0
interfaces:
- eth0
- eth1结构体:
type MetalLBServiceL2Status struct {
Node string
Interfaces []InterfaceInfo
}
type ServiceL2Status struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Status MetalLBServiceL2Status `json:"status,omitempty"`
}
type InterfaceInfo struct {
Name string `json:"name,omitempty"`
}问题分析
要实现状态显示,我们要解决的核心问题有以下两个:
- 什么时候刷新状态:这个问题比较直接。基于k8s控制器的基本逻辑,容易想到只需要在service的reconcile函数里调用状态更新函数即可。这样每次service有变化,都会幂等地刷新其状态。
- 如何获取状态:根据上面CRD的设计,我们需要的状态主要包含service流量转发的node和网卡信息。那么必须弄明白的就是这些信息是在哪里确定下来的。
controller or speaker
带着上面两个问题,需要去代码里寻找答案了。但是在开始前,还有一个重要的问题需要确定。由于metallb包含两个组件,一个是controller,单pod,另一个是speaker,使用daemonset部署在所有节点上。所以我们必须先确定需要的信息是由controller和speaker中的哪个组件决定的。
-
上篇对metallb代码进行分析的文章中,涉及到的主要逻辑都是在speaker里,而controller的逻辑还没太总结。因此先总结一下controller的代码逻辑。直接看controller的main函数:
// controller初始化,只需要实例化一个IP allocator c := &controller{ ips: allocator.New(), } // 给k8s informer配置reconcile函数 cfg := &k8s.Config{ ... Namespace: *namespace, Listener: k8s.Listener{ // service reconcile ServiceChanged: c.SetBalancer, // ip pool config reconcile PoolChanged: c.SetPools, }, ... } -
controller.SetBalancer
func (c *controller) SetBalancer(l log.Logger, name string, svcRo *v1.Service, _ epslices.EpsOrSlices) controllers.SyncState { ... // 删除service时,清理状态 if svcRo == nil { if c.isServiceAllocated(name) { c.ips.Unassign(name) level.Info(l).Log("event", "serviceDeleted", "msg", "service deleted") // There might be other LBs stuck waiting for an IP, so when // we delete a balancer we should reprocess all of them to // check for newly feasible balancers. return controllers.SyncStateReprocessAll } return controllers.SyncStateSuccess } ... // 核心逻辑,为service管理ip分配 if c.convergeBalancer(l, name, svc) != nil { syncStateRes = controllers.SyncStateErrorNoRetry } ... } -
controller.SetPools
func (c *controller) SetPools(l log.Logger, pools *config.Pools) controllers.SyncState { ... // 核心只有两行,根据pools,整理出ip池,绑定到controller上,供svc分配ip用 c.ips.SetPools(pools) c.pools = pools ... } -
综上,可以看到controller的任务还是比较清晰明了的,它主要负责LB service的IP分配,和本次要实施的ServiceL2Status关系不大。
node状态
再次聚焦到metallb的speaker模块。之前对speaker的代码分析中,主要围绕其layer2模式下arp相关的核心流程进行。这次,我们需要着重分析,speaker对于arp广播状态的改变是如何实现和维护的,从而确定出在什么情况下需要刷新状态。
-
首先还是要牢记speaker对arp的控制分为两部分,一部分是状态变化后的免费arp;另一部分是arp responder daemon,负责持续监视arp req,发送arp reply。
-
免费arp的发送,都是在
layer2Controller.ShouldAnnounce函数后的,所以layer2Controller.ShouldAnnounce函数是确定speaker是否负责流量转发的核心函数,因此状态相关的维护操作也应该在其后面进行。 -
另一方面,每个节点speaker的arp responder在监听arp req,发送reply前,也会有一个shouldAnnounce函数,判断是否需要本speaker回应:
func (a *Announce) shouldAnnounce(ip net.IP, intf string) dropReason { a.RLock() defer a.RUnlock() ipFound := false // 从Announce.ips中找ip,看看是否该ip由本speaker负责 for _, ipAdvertisements := range a.ips { for _, i := range ipAdvertisements { if i.ip.Equal(ip) { ipFound = true // 再对比一下网卡是否匹配 if i.matchInterface(intf) { return dropReasonNone } } } } if ipFound { return dropReasonNotMatchInterface } return dropReasonAnnounceIP } -
综上可以得出以下事实:
- speaker reply前,要去
Announce.ips里去找一下,ip是否归自己负责,是的话,再发送。 - 而
Announce.ips的维护,是在Announce.SetBalancer函数中完成的。 - 而
Announce.SetBalancer的调用,也是要在layer2Controller.ShouldAnnounce函数后完成的。 - 因此,最终节点的选择,核心还是取决于
layer2Controller.ShouldAnnounce函数的结果。
- speaker reply前,要去
-
由此可得初步的结论:我们只需要在
layer2Controller.ShouldAnnounce函数之后把节点信息写进CR即可。
interface状态
上面我们重点关注了node选择的问题,在该过程中,也有interface相关的逻辑,这里我们也一同梳理一下。
首先还是看免费arp的流程,在之前的代码分析中,我们已经分析过了网卡过滤相关的逻辑,其中和免费arp相关的主要在这个函数里
// 该函数在layer2Controller.ShouldAnnounce之后执行,即,确定本节点需要announce后,进行后续操作
func (c *layer2Controller) SetBalancer(l log.Logger, name string, lbIPs []net.IP, pool *config.Pool, client service, svc *v1.Service) error {
ifs := c.announcer.GetInterfaces()
for _, lbIP := range lbIPs {
// 输入lb IP,节点信息,L2Advertisements CR,给出layer2.IPAdvertisement,其中包含了ip和interface
ipAdv := ipAdvertisementFor(lbIP, c.myNode, pool.L2Advertisements)
// layer2.IPAdvertisement和Announce的interface做交集匹配
if !ipAdv.MatchInterfaces(ifs...) {
level.Warn(l).Log("op", "SetBalancer", "protocol", "layer2", "service", name, "IPAdvertisement", ipAdv,
"localIfs", ifs, "msg", "the specified interfaces used to announce LB IP don't exist")
client.Errorf(svc, "announceFailed", "the interfaces specified by LB IP %q doesn't exist in assigned node %q with protocol %q", lbIP.String(), c.myNode, config.Layer2)
continue
}
c.announcer.SetBalancer(name, ipAdv)
}
return nil
}
func ipAdvertisementFor(ip net.IP, localNode string, l2Advertisements []*config.L2Advertisement) layer2.IPAdvertisement {
ifs := sets.Set[string]{}
for _, l2 := range l2Advertisements {
if matchNode := l2.Nodes[localNode]; !matchNode {
continue
}
if l2.AllInterfaces {
return layer2.NewIPAdvertisement(ip, true, sets.Set[string]{})
}
ifs = ifs.Insert(l2.Interfaces...)
}
return layer2.NewIPAdvertisement(ip, false, ifs)
}然后再继续确认下arp daemon的网卡选择相关逻辑,其实还是上面节点选择时用到的函数
func (a *Announce) shouldAnnounce(ip net.IP, intf string) dropReason {
...
// 从Announce.ips中找ip,看看是否该ip由本speaker负责
for _, ipAdvertisements := range a.ips {
for _, i := range ipAdvertisements {
if i.ip.Equal(ip) {
ipFound = true
// 再对比一下网卡是否匹配
if i.matchInterface(intf) {
return dropReasonNone
}
}
}
}
if ipFound {
return dropReasonNotMatchInterface
}
...
}从代码实现逻辑可以看出,speaker在确定某个lb ip归自己节点负责后,会通过生成IPAdvertisement,确定网卡选择的结果(主要依据是L2AdvertisementCR)。
再往后到了实际arp响应的阶段,对应于所有未被排除的网卡,都会有一个daemon负责在该网卡上响应arp reply,而每个arp daemon在发送arp reply前,要通过i.matchInterface确认一下自己是不是对应的网卡。不过这个阶段和我们的状态展示关系不大。
实际上和本次功能开发关系最密切的正是IPAdvertisement对象,这也是直接反应speaker在arp广播方面状态的对象。
功能实现
Go type
由于本次feature需要新增一个CRD,所以需要从对应的go type开始创建,后面再大体按照go types -> auto generated codes -> CRD -> CR example的顺序进一步完善整个类型系统的新增。
欲新增一个CRD,先确定API版本。查看目前metallb仓库里有的Version包含以下三个:
❯ tree -L 1 -d
.
├── v1alpha1
├── v1beta1
├── v1beta2
└── validate此时需要先复习一下k8s中GVK(Group/Version/Kind)中和V相关的兼容性设计了。
- 首先明确,k8s中同一个G和K,可以在多个V中存在,且多个V中的字段可以出现不向后兼容的改动
- 不同V之间的同一个K,通过转换函数或者转换webhook明确不兼容字段的转换逻辑,实现版本兼容
- 对于新增的K,无需关心这个问题
顺便观察一下已经安装的metallb的CRD信息
# 查看最新的版本
❯ helm search repo metallb
NAME CHART VERSION APP VERSION DESCRIPTION
bitnami/metallb 4.7.3 0.13.11 MetalLB is a load-balancer implementation for b...
metallb/metallb 0.13.11 v0.13.11 A network load-balancer implementation for Kube...
# 查看当前安装的版本
❯ helm list -n metallb
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
metallb metallb 3 2023-09-25 16:26:17.288647 +0800 CST deployed metallb-0.13.10 v0.13.10
# 查看当前版本CRD的api情况
❯ k api-resources --api-group=metallb.io
NAME SHORTNAMES APIVERSION NAMESPACED KIND
addresspools metallb.io/v1beta1 true AddressPool
bfdprofiles metallb.io/v1beta1 true BFDProfile
bgpadvertisements metallb.io/v1beta1 true BGPAdvertisement
bgppeers metallb.io/v1beta2 true BGPPeer
communities metallb.io/v1beta1 true Community
ipaddresspools metallb.io/v1beta1 true IPAddressPool
l2advertisements metallb.io/v1beta1 true L2Advertisement
# 查看某个CRD的细节
❯ k explain ipaddresspools.spec
KIND: IPAddressPool
VERSION: metallb.io/v1beta1
RESOURCE: spec <Object>
DESCRIPTION:
IPAddressPoolSpec defines the desired state of IPAddressPool.
...后来发现,design里给出的CRD字段已经包含了明确的GVK,所以这个问题就不用再过多探索了,先直接用design里的即可。
接下里到了动手实施的时候了。
整体上看,metallb的项目目录结构和kubebuilder生成的项目的结构大体相似,api目录里的go types也有很多kubebuilder的标签,猜测项目也是基于kubebuilder实现的。因此直接尝试用kubebuilder增加新API。
但是当我们尝试用kubebuilder命令去创建api时,发现并不能成功:因为项目并没有kubebuilder项目的元数据,所以无法识别metallb的仓库为kubebuilder项目。这也说明目前这些api并不是直接用当前版本的kubebuilder生成的。但是鉴于在api目录中出现的大量kubebuilder marker,所以猜测应该还是用了kubebuilder生态的工具链去实现的,只是和当前最新的kubebuilder文档中的使用方式不太一样。
❯ kubebuilder create api --version v1beta1 --kind ServiceL2Status --group metallb.io
Error: failed to create API: unable to load configuration file:
unable to load the configuration:
unable to read "PROJECT" file: open PROJECT: no such file or directory同样,尝试为其建立元数据也是不可行的,kubebuilder不支持在非空项目中初始化项目。
经过和社区maintainer沟通,确认了该项目由于历史发展原因,和kubebuilder属于同时成长,所以流程上和现在kubebuilder的使用方法并不完全匹配。
因此,api目录中的go types目前只能通过手写来完成了。好在工作量不大,目前手写也可以接受。
marker
参照api目录中已有的CRD types写好本次要新加的ServiceL2Status结构体定义后,需要为结构体增加marker,使得代码生成器能够识别到,进而生成更多固定结构的代码。如果是用kubebuilder命令生成的api,那么一些通用的marker都是默认写好的。由于本次的结构体定义完全手写,所以也需要手动地添加marker,比如这几个:
// +kubebuilder:object:root=true
// +kubebuilder:subresource:status
// +kubebuilder:storageversion以上是最基本的几个marker,需要为CRD的一级结构体添加,除此之外,对于CRD的List容器,也需要添加
// +kubebuilder:object:root=true除了以上比较核心的marker,还有一些额外小功能类的marker,帮助CRD跟更好用,比如下面这个,可以为kubectl get $cr时增加显示输出的列
// +kubebuilder:printcolumn:name="Allocated Node",type=string,JSONPath=`.status.node`更多关于marker的具体信息,可以参考官方文档。
生成deepcopy代码
首先,以前有一个独立的项目叫deepcopy-gen,专门用来生成CRD对应go type的deepcopy函数。
不过现在并不需要使用单独的deepcopy-gen了,controller-gen即可生成deepcopy类代码:
./build/bin/controller-gen object paths=api/v1beta1/servicel2status_types.go output:dir=./在使用controller-gen生成deepcopy代码时,遇到几个小坑
-
paths参数后的路径,如果使用
./开头,会报路径类的错误 -
本次定义的结构体,status字段对应的结构体中不全是基本类型,仍然有结构体嵌套,这时生成的deepcopy代码会使用到中间嵌套结构体的deepcopy method,而默认是不会为中间嵌套的结构体生成deepcopy代码的。这时需要手动添加marker,为中间结构体生成deepcopy代码
// +kubebuilder:object:generate=true // MetalLBServiceL2Status defines the observed state of ServiceL2Status type MetalLBServiceL2Status struct { // Node indicates the node that receives the directed traffic Node string `json:"node,omitempty"` // Interfaces indicates the interfaces that receive the directed traffic Interfaces []InterfaceInfo `json:"interfaces,omitempty"` } -
metallb的仓库未对该操作的命令进行展开描述,还需要自己踩一些坑
CRD
完成上述go代码相关的工作后,就可以根据该结构体生成CRD的yaml了,因为后续功能实现后,必然需要到集群里开发调试测试,所以这一步早些完成也是极好的。
在dev-env目录的readme中,可以看到其中提到了开发工具,其中同样有提到controller-gen。kubebuilder中同样也大量使用该代码生成工具。搜github发现该工具目前位于kubernetes-sigs/controller-tools: Tools to use with the controller-runtime libraries (github.com)仓库(记得以前是有独立仓库的,可能后来改了)。
另外观察项目的编译工具invoke所使用的脚本,其中有CRD生成相关的命令
def generate_manifest(ctx, crd_options="crd:crdVersions=v1", bgp_type="native", output=None, with_prometheus=False):
_fetch_kubectl()
run("GOPATH={} go install sigs.k8s.io/controller-tools/cmd/controller-gen@{}".format(build_path, controller_gen_version))
res = run("{}/bin/controller-gen {} rbac:roleName=manager-role webhook paths=\"./api/...\" output:crd:artifacts:config=config/crd/bases".format(build_path, crd_options))可以看到,这里会使用go install安装指定版本的controller-gen,然后基于api目录下的go types生成webhook配置和crd yaml到config目录里。
因此只需要inv generatemanifests即可
client
该项目发展早期没有使用CRD机制,只使用configmap存储配置文件,然后读取即可。后来开始转向CRD机制后,把配置管理相关的功能迁移到了CRD中,项目中比较常见的CRD的用法是从CR中读取配置,向CR中更新状态的用法还不太多。
本次新增的CRD,恰好就是和之前CRD用法相反的类型:核心工作是更新status,而无spec和Reconcile。
既然需要更新status,我们就需要了解一下目前项目里使用到了什么样的k8s client来操作k8s objects。
// 这里可以看到熟悉的client使用方式,kubebuilder也是使用了controller-runtime里封装的client,可以方便地同时支持原生对象和CRD的CRUD
// internal/k8s/controllers/config_controller.go:57
var requestHandler = func(r *ConfigReconciler, ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var addressPools metallbv1beta1.AddressPoolList
if err := r.List(ctx, &addressPools, client.InNamespace(r.Namespace)); err != nil {
level.Error(r.Logger).Log("controller", "ConfigReconciler", "message", "failed to get addresspools", "error", err)
return ctrl.Result{}, err
}
}
// client的注入
// internal/k8s/controllers/config_controller.go:41
type ConfigReconciler struct {
client.Client
...
}因此后续我们也尽量参照这种方式,使用该client去读写CRD。
核心思路
在动手写代码前,先梳理一下整体的逻辑,并且保证逻辑的幂等性:
-
如果一个service是LoadBalancer类型,某个layer2 speaker确定了将为其代理arp响应,那么此时应该把代理的node和interface更新到本次新增的CR中。
-
反之,如果一个service不再满足layer2模式的要求(不再是lb类型等),应当删除其对应的状态CR。
实现功能
后记:初步实现,后面就被推翻重新设计了。
- 接口设计:在阅读了该项目已有的一些操作对象的接口后,仿照设计了类似的管理状态的接口
- k8s crud层实现:设计了一个对象,实现上述接口,负责layer2 status对象的管理
- layer2_controller调用:在service状态发生变化时,layer2_controller会维护service的状态,在这里增加对2中对象的调用,即可同时完成对状态CR的维护
本地调试
根据文档描述,使用inv dev-env --protocol layer2,可以快速在本地使用kind拉起集群,并部署metallb。在首次跑起来调试的过程中,会遇到很多细节问题:
-
除了核心代码逻辑,需要了解部署用到的yaml是如何生成的,这些yaml和之前用controller-gen生成的yaml有何关系,本地部署是否会用到helm chart等:这些问题的答案都在
task.py的代码逻辑中 -
新增的CRD,需要增加RBAC,包括status子资源
-
client.Create不负责更新status子资源:需要单独调用status.update
-
卸载后,各个命名空间的cr怎么处理:不需要额外处理,能跟随metallb一起正常删除
-
即使不使用bgp模式,只使用layer2模式,bgp相关的代码也需要编译。而默认使用的native type bgp,由于和linux操作系统底层有直接关联,会导致metallb的speaker在mac环境无法跑起来。因此最好使用linux环境来调试。
-
修改dev-env拉起的kind集群的配置:
def dev_env(ctx, architecture="amd64", name="kind", protocol=None, frr_volume_dir="", node_img=None, ip_family="ipv4", bgp_type="frr", log_level="info", helm_install=False, build_images=True, with_prometheus=False, with_api_audit=False): ... if mk_cluster: config = { "apiVersion": "kind.x-k8s.io/v1alpha4", "kind": "Cluster", "nodes": [{"role": "control-plane"}, {"role": "worker"}, {"role": "worker"}, ], # apiserver监听的地址和端口 "networking": { "apiServerAddress": "10.10.10.105", "apiServerPort": 6443, } } .... -
在运行
inv dev-env时如果加了--protocol layer2参数,脚本会从docker network中找出可用的ip作为ip池,并建立layer2模式下的ip池yaml对象。但是实际使用中发现tasks.py的get_available_ips函数有bug,无法正常获取到node的ip,不知道是不是和ipv6有关系。所以在开发调试阶段可以不加--protocol layer2参数,手动根据dev-env/layer2/config.yaml.tmpl生成yaml,根据kind集群node的网段,创建IPAddressPool和L2Advertisement对象。 -
使用idea IDE时,启动时会有go workspace相关的报错。
/usr/local/opt/go/libexec/bin/go list -m -json -mod=readonly all #gosetup go: k8s.io/endpointslice@v0.0.0: invalid version: unknown revision v0.0.0 # 手动在e2etest目录执行命令重现错误 ❯ go list -m -json all go: k8s.io/endpointslice@v0.0.0: invalid version: unknown revision v0.0.0这个问题是涉及到k8s代码引用比较常见的,遇到这种问题,需要把对相关包的引用replace成特定版本的包:
replace ( ... k8s.io/endpointslice => k8s.io/endpointslice v0.28.2 ... )
invoke工具的使用需知
metallb项目的构建工具没有使用Make,而是使用了一个基于python的invoke。好处是基于python,比make的语法可读性高些;坏处是相对小众,需要稍微学习一下。以下是一些有必要了解的内容:
-
py函数名称和函数里参数的下划线在命令行中需要转成中划线:比如
def dev_env(bgp_type="frr")对应的命令行为inv dev-env bgp-type='frr' -
布尔值转成参数不能用True/False,要用类似于自然语言的形式表达肯定/否定
# 例 def dev_env(ctx, architecture="amd64", name="kind", protocol=None, frr_volume_dir="", node_img=None, ip_family="ipv4", bgp_type="native", log_level="info", helm_install=False, build_images=True, with_prometheus=False, with_api_audit=False): passhelm_install和build_images两个bool类型的参数转成命令行后的格式如下:
inv dev-env --protocl layer2 --helm-install --no-build-images
code review
round1
如上文所述,在初步实现功能,本地验证无误后,我在github发起了PR,请项目管理员(后面称其为oribon)瞥一眼我的代码。
很快oribon给出了架构设计角度的建议:
我的实现基于原有的controller进行了扩展和修改,他建议直接增加一个新的控制器,专门负责layer2 status cr的reconcile。这样的设计更符合开闭原则,也更纯粹,当然也更符合k8s声明式API的设计,也更cloud native。
于是我按照他的建议重新按照新的方式进行了实现:
- 增加layer2_status_controller
- 上述controller watch一个channel
- 已有的layer2_controller在维护service状态时,同步向channel中发送event,通知layer2_status_controller对相应的状态CR进行维护
- layer2_status_controller在维护CR时,需要知道对应service在speaker内部的状态,所以layer2_status_controller在实例化时需要被注入一个function,通过该function获取到speaker的内部状态
round2
上述修改完成后,我再次请oribon进行review。这次review的建议如下:
- 加e2e test
- 加unit test
- go best practices
- 其他一些实现细节的优化和个人偏好建议
顺便在这里整理一下常用黑话
nit: nit-pick, Nitpicking is the action of giving too much attention to unimportant detail.
从行为上,可以对标鸡蛋里挑骨头,不过中文语境这个描述是贬义的,nit是中性的
wdyt: what do you think
cc: 抄送e2e测试
为了方便后面对核心代码的优化,我考虑先增加e2e测试和单元测试,确保功能正常,这样后面修改核心代码可以通过这些测试快速确认功能的正常。
metallb主要使用了ginkgo测试框架进行端到端的测试。
ginkgo关键概念和用法:
-
核心用例在it语句中
-
describe/context是容器类语句
-
支持用例过滤(focus、pending等)
类似于上面提到的问题,在mac上跑e2e test发现metallb e2e test中的某些用例无法在mac上正常跑,因为用到一些网络相关的工具和命令,mac上是没有的,比如ip,因此在ubuntu上重新搭建了环境,在mac上写代码,用idea的自动同步功能同步到linux vm上,然后进行调试。
以下是设计的测试用例:
- 当我们新建一个lb类型的service时,最终可以找到一个与之对应的
ServiceL2Status对象,且`ServiceL2Status对象中的字段值符合预期(speaker node正确,网卡正确) - 当node状态变化(down掉,重新恢复)时,验证1中的项目依然没问题
- 上述lb service的状态变化(被删除、类型不再是LoadBalancer)时,对应的
ServiceL2Status对象被删除 - 更广泛地讲,已有的很多测试用例都会改变announcing status,相对应的,我们的状态CR应该同步被更新,并验证状态正确。但是这一点对应的工作量会很大,初期可以先不考虑。
ginkgo技巧
在使用ginkgo时,遇到了一些问题,相应也有一些小技巧:
-
概览一下要跑哪些用例,及对应的描述
inv e2etest --focus L2 --bgp-mode native --ginkgo-params="--dry-run -v" -
精确focus到个别用例
inv e2etest --bgp-mode native --focus 'should work for ExternalTrafficPolicy=Cluster|Validate ServiceL2Status interface' -
跑e2e测试时如果ctrl+c中断,那么afterSuite中的清理工作会无法完成,此时需要删了环境重新拉起
inv dev-env-cleanup
round2修改
- 接口的定义应该放到使用接口函数的包中,而不是定义在实现接口的包中:https://go.dev/wiki/CodeReviewComments#interfaces
- client-go中的cache包封装了拆meta的函数,每次想用时都想不起来在哪里
cache.SplitMetaNamespaceKey(name) - 如何幂等地将cr保存集群中:
controllerutil.CreateOrUpdate,类似于HTTP.Put - 其他tiny details
单元测试
e2e测试包含了很多场景,是比较综合的测试。而单元测试只关注控制器本身的行为,比如本次增加的单元测试只验证控制器监听的channel收到元素后,是否能正常reconcile,而不关心channel收到元素之前,其他组件的行为。
跑所有单元测试
#在使用inv test前,需要先清理一下build目录,否则build目录中的包也包含单元测试,会一起运行
inv test后面开发调试过程中,有一些情况我们不需要跑所有的单元测试,就不需要inv test了。可以单独使用go test只跑一部分测试,但是此时需要加环境变量指定mock环境的目录:
KUBEBUILDER_ASSETS=/root/go/src/metallb/dev-env/unittest/bin/k8s/1.27.1-linux-amd64 go test ./internal/k8s/controllers进一步,还可以继续降低单元测试的粒度,只跑个别测试用例,同样还是使用ginkgo的focus功能,并可以使用--ginkgo.v --test.v调整ginkgo和go test的日志级别
KUBEBUILDER_ASSETS=/root/go/src/metallb/dev-env/unittest/bin/k8s/1.27.1-linux-amd64 go test ./internal/k8s/controllers --ginkgo.focus='Layer2 Status' --ginkgo.v --test.v但是测试中实例化的各类controller本身的日志并不受控于这两个参数。controller实例的日志,需要根据其logger类型,配置合适的logger实例,并使用GinkgoWriter作为writer,比如
import (
"github.com/go-kit/log"
)
...
log.NewLogfmtLogger(GinkgoWriter)CI Workflow
DCO
之前给kubeedge提交代码知道了DCO test,以及实践了一次如何给commit补签。
这次在初期提交的几十个commit中,不幸混入了两个commit没有sign,导致没有通过DCO Test。因此需要使用git rebase修改commit信息,重新sign。
在经过修改后,DCO Test成功通过了,但是发现我的commit 信息中混入了其他committer的commit,使得我的commit log非常之乱。
但是到后来我才发现一个问题:DCO Test虽然在workflow中是第一个跑的,但是其实是应该最后修正的,因为它需要跟随最终的commit,如果代码还在频繁修改,后面肯定还需要各种rebase,中间阶段修正DCO是没有意义的,除非DCO真的成为阻塞其他workflow运行的原因。
关于rebase
- 如果冲突代码很多,rebase很麻烦,不如git reset重新同步后一次性解决冲突,重新提交。这种操作不影响github pr。
- 在不断merge origin的过程中,fork仓库会不断混入其他人的commit,最后rebase时应该注意顺序,把其他人的commit放在最早,这样相当于我们的修改是基于之前所有commit完成的最新的修改,后续review和merge都会比较干净。
其他
按照.github目录中workflow里的ci.yml,逐个比对ci的流程,修复import等代码格式类的问题。
过程中发现对mac不太友好。很多命令还是在linux下跑比较顺。
就这样,中间我又提交了一些commit,修复各种ci workflow错误,一直到下次oribon再次提出一些review。
round3
很快oribon又提出了最新的建议,主要有以下几类
-
对于之前提到的几处函数参数的定义稍有反悔,revert掉了;变量命名等小细节。
-
补充单元测试和e2e测试中的细节,主要是验证多个controller实例不会冲突。
-
最重要的,提到了controller reconcile函数的幂等实现问题。之前实现的时候这里有一些疑惑还没彻底解决,这次边讨论边搜索,一下就找到了解决方案。说起来也很简单,就是controller-runtime提供的两个工具函数的用法问题,一个是
CreateOrUpdate,另一个是CreateOrPatch,这俩对subresource的支持是不一样的,之前看代码没看到详细的提示,这次在google搜到go pkg里的文档,很明确地给出了提示。 -
修改过程中开发环境又遇到了一些麻烦的问题:
inv dev-env向本地kind集群更新镜像时,有时候会出现containerd的报错:ERROR: failed to load image: command "docker exec --privileged -i kind-worker2 ctr --namespace=k8s.io images import --all-platforms --digests --snapshotter=overlayfs -" failed with error: exit status 1 Command Output: unpacking quay.io/metallb/speaker:dev-amd64 (sha256:710426e898d50892ade13efda66289df2bde47a942b167d572fd2d72dbf57de5)...time="2024-01-31T05:54:08Z" level=info msg="apply failure, attempting cleanup" error="wrong diff id calculated on extraction \"sha256:a6e44f4e7f6b9f986b3a7a47972ceccea6ae764545a6cc2ff9ee9b76207c95e7\"" key="extract-121215395-KIvP sha256:f334d63dec8589607815daf0b24010e2258a4d90e5daf69ed6426cf1bd0b0b71" ctr: wrong diff id calculated on extraction "sha256:a6e44f4e7f6b9f986b3a7a47972ceccea6ae764545a6cc2ff9ee9b76207c95e7"没找到根本原因和彻底的解决办法,临时的解决方案是手动清理开发环境和kind节点的镜像
for node in kind-control-plane kind-worker kind-worker2;do docker exec --privileged -it $node ctr -n k8s.io images rm quay.io/metallb/speaker:dev-amd64;done for node in kind-control-plane kind-worker kind-worker2;do docker exec --privileged -it $node ctr -n k8s.io content prune references;done docker rmi quay.io/metallb/speaker:dev-amd64
遇到难点
在进行round3的修改过程中,我发现我和oribon对于本次新增的控制器的行为理解有一点偏差:
我的实现:
- 控制器通过
WatchesRawSource监听了一个channel,对channel中的对象做出反应,进行reconcile从而将状态CR持久化到集群中。 - 在开发中,发现这种同时监听channel,同时又监听集群CR的控制器很容易出现无限循环的链式reconcile,且难以通过reconcile逻辑去修正。
- 所以面对这种情况,使用predicate,直接把来自集群的CR变化事件全部过滤掉,只对channel中的元素变化做出反应
- 这样的实现逻辑简单,不会有链式反应;但是弊端是,如果一个用户或其他控制器修改了集群里的CR,我们的控制器并不会对其有响应。
oribon的预期:
- 希望控制器能同时对集群里的CR变化做出反应,以确保状态类CR能够永远受控制器的管理
尝试解决
某个周五晚上,下班回家吃饱喝足后,我开始思考这个问题。
首先问题的本质如下图所示,我们的控制器跑在speaker里,而speaker最终是daemonset部署,会有多副本,而每个speaker各自有内部状态,彼此并不知道其他speaker中的状态。因此想让多个controller共同维护一个非中心化状态的CR是不可能的
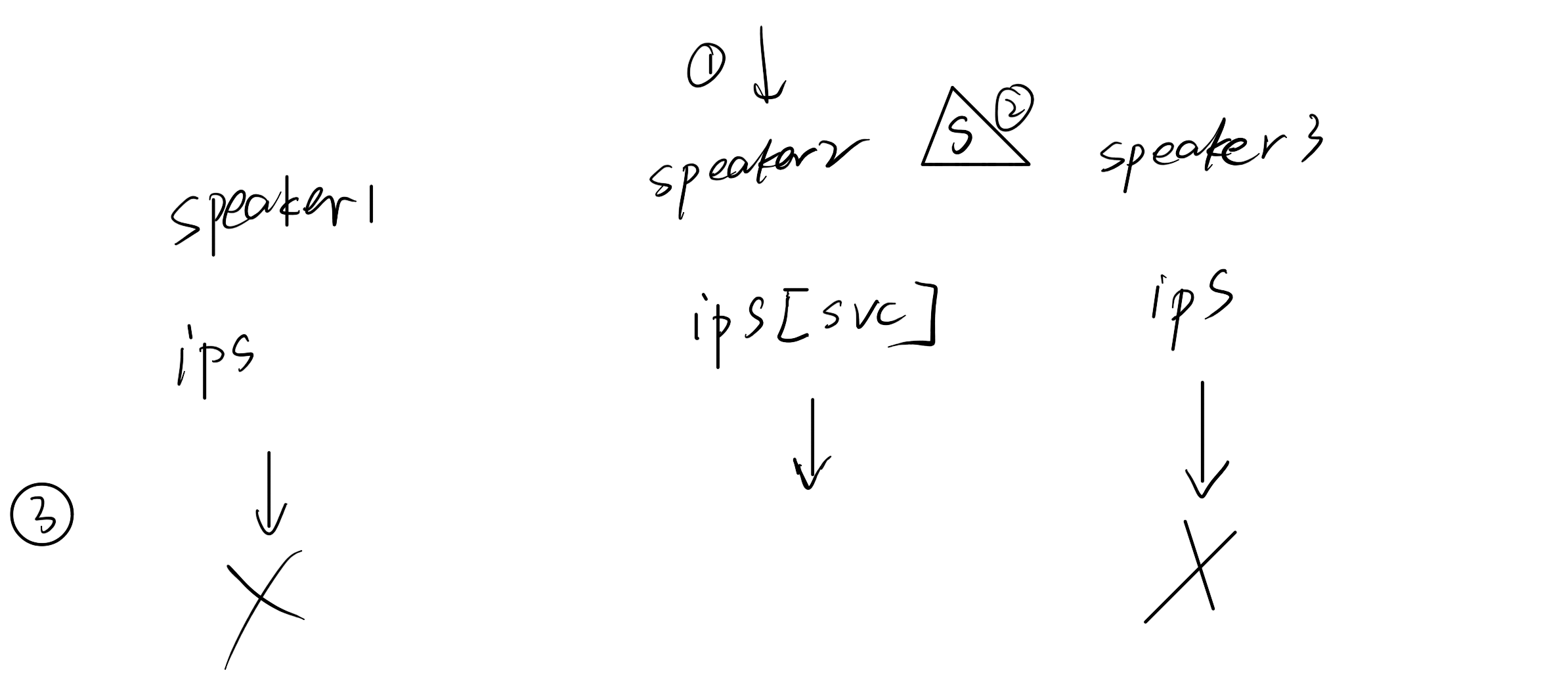
针对这种情况,我设计了几种可能的解决方案

其中1是我之前的实现方法,为了满足oribon对控制器的更高要求,我采用了方案4,将集群中service的状态作为一个中心化的状态来源,这样就解决了多个控制器缺少中心化状态无法达成共识的问题
但是显然这个方案总感觉是个workaround,并不是十分优雅和完美。
请外援
oribon cc了另一个maintainer fedepaol,向其征求了意见。
fedepaol给出了一个新的方案:fedepaol的建议修改控制器模型,由多副本控制器共同维护一个CR,改为多副本控制器各自维护各自的CR,这样不会产生冲突。每个speaker以其node name作为唯一标识,添加到CR的name中,相当于各自划分领地,各自为王,互不干涉。这样就不需要中心化的状态了。
按照fedepaol的建议,我终于完成了round3的修改。虽然修改了控制器的模型,但是反而让reconcile函数的实现变得很简单了,因为不再需要考虑复杂的状态维护。
启示:有时候做一件事发现太复杂太难走到了死胡同的时候,除了考虑做这件事的方法是否正确意外,还可以大退一步甚至多步,看看方案和思路上有没有可能优化。当我看完fedepaol给出的新方案的时候,我深刻地体会到了什么叫退一步海阔天空。
round4
- 使用
handler.EnqueueRequestsFromMapFunc,对控制器的Request进行改写,统一来自集群和来自channel的目标的命名,这样reconcile函数可以统一逻辑 - 尽量减少使用else分支,把所有的if逻辑都简化
- 使用eventFilter过滤掉命名不符合规则的CR:对于管辖范围内的CR,我们一管到底,增删改查控制器都会管;对于命名规则不对,即不是由控制器创建出来的CR,控制器完全不干预
- 测试中出现了一处race condition,通过加锁解决
- 其他一些nits
这轮review和修改,见识到了一些高级的控制器写法,也加强了对if else的优化意识,受益匪浅,十分感谢oribon。
todo
虽然本次功能实现了,但是在整个过程中,还有一些点可以进一步深入研究和学习:
- dev-env中有一个参数
--with-api-audit:可以借此了解api server的audit逻辑 - 修复
inv dev-env --protocal layer2中ip获取错误的bug
参考
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。