使用chatgpt-on-wechat自动回复祝福微信
背景
2018年,用itchat实现了一个非常简单的自动回复小程序,对祝福微信进行快速回复。现如今来到了2024年,LLM大火,我们的自动回复小程序也终于可以接入chatgpt了。如此一来,可以让回复更加智能、生动。
部署chatgpt-on-wechat
项目原生支持railway这种快速部署平台,可以解决openai接口调用时的国家限制问题,并且支持自动更新,部署十分方便。
部署完成后,在service env中配置一些基本的环境变量:
{
"open_ai_api_key": "sk-xxxx",
"model": "gpt-4",
"character_desc": "作为一个龙年祝福回应助手,你负责对收到的祝福进行回应。因为今年是农历龙年,所以你要尽量用包含龙年元素的祝福回应,祝福语应积极向上,富有创意,使用现代网络语言和表情符号,增加亲和力。比如🐲龙年大吉,好运当头!新年快乐!。但是如果你判断收到的内容不是新年祝福,那么就用简短、友好的方式介绍你自己。",
"single_chat_prefix": "[\"\"]",
"single_chat_reply_prefix": "[AI助理] ",
"hot_reload": "True",
}然后去railway service中查看deploy log,会打印出微信登录二维码,用微信账号扫描登录,即可开始自动回复。
遇到问题
该项目默认对私聊进行回复时,只支持按前缀匹配,比如设置single_chat_prefix=["bot"],那么只有收到的消息以bot开头,才会触发该程序调用openai接口去回复。
而新年祝福类的微信,前缀不确定性太大,无法简单地用前缀匹配。如果设置single_chat_prefix=[""]即对所有私聊消息都进行回复的话,会干扰正常微信聊天。
修改代码
参考前缀匹配的方法,我fork该项目后,增加了一处配置"single_chat_keywords": "[\"新年\", \"龙\", \"祝\"]",并增加逻辑,按照消息关键字进行匹配,只对包含这些关键字最少一个的消息进行自动回复
再次部署
直接修改代码后,会发现railway自动部署了(前提是railway关联了fork后的项目),但是奇怪的是发现并没有生效,看日志发现日志输出的代码行数和修改后的代码并不匹配,代码的修改并没有反映在railway的自动部署中。
这还是蛮奇怪的,查看railway dashboard发现每次部署的代码commit都是无误的。
发现部署玄机
最后研究了半天项目的部署,发现这其中的玄机在于railway默认用到的dockerfile并不是我想当然的基于代码构建的,而是一个固定的base image,相当于每次重新部署并不会改变代码。
FROM ghcr.io/zhayujie/chatgpt-on-wechat:latest
ENTRYPOINT ["/entrypoint.sh"]想修改代码,需要将修改后的代码打成镜像,作为上述dockerfile的base image才可以。而真正的基于代码构建docker image的dockerfile位于项目的docker子目录中
效果
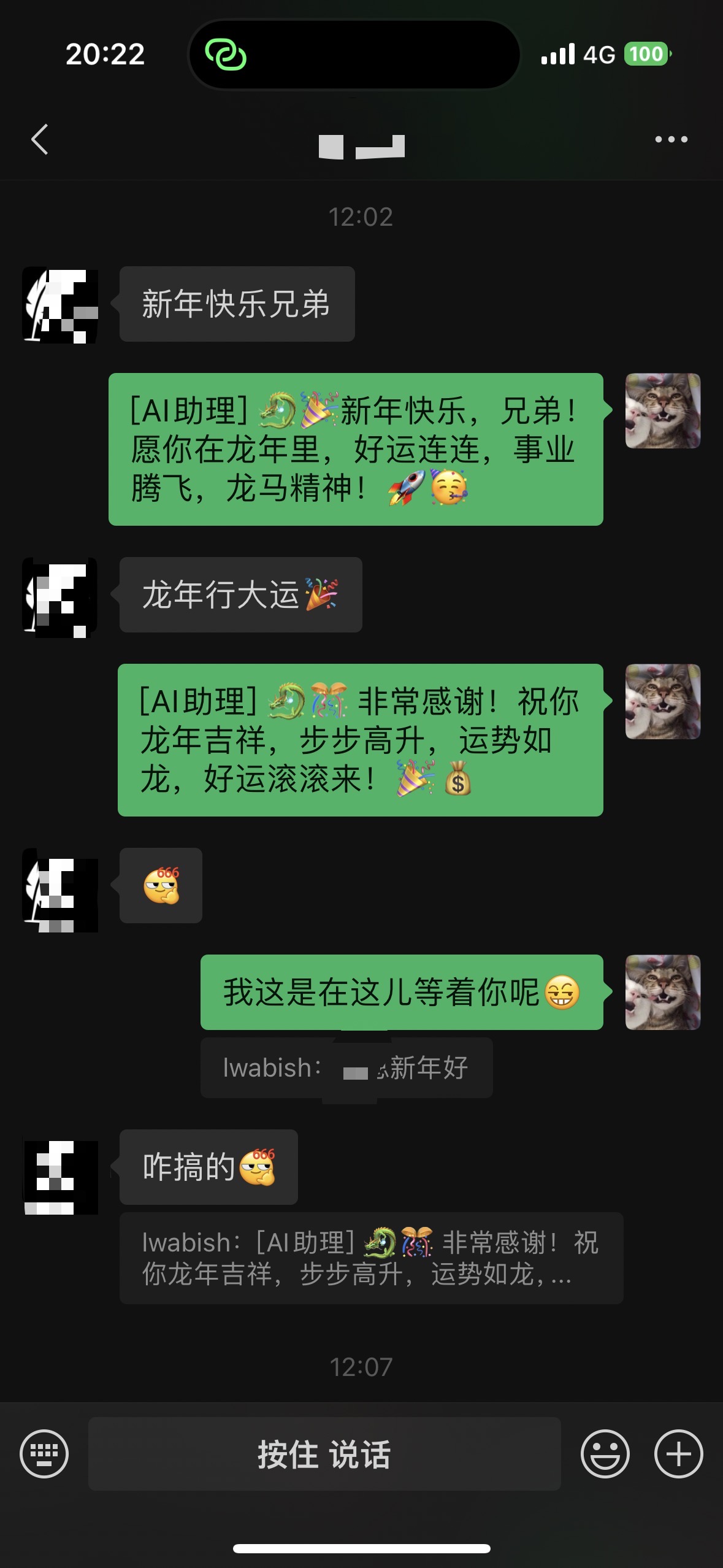
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。